Obsrv.tech + RL environments + custom SLMs
Make your AI reliable, cost effective, and usable.
thetalab turns live production runs into evidence, converts the hard cases into RL environments, and trains private small models for your exact company workflow.
01
Observe
Capture what happened in production.
02
Simulate
Turn hard cases into safe RL environments.
03
Train
Move repeat work into a private small model.
Why thetalab
Reliability is a business system, not a better prompt.
Enterprises need AI that can be debugged, benchmarked, improved, and owned. thetalab connects those steps into one operating loop.
Start from evidence
Every live run becomes a trace your team can replay, annotate, search, and turn into a training signal.
Practice the hard cases
Failures, messy data, timeouts, policy checks, and handoffs become repeatable tasks in a safe environment.
Own the repeat work
High-volume workflows move into a workflow-specific SLM with lower cost, controlled behavior, and a live feedback loop.
01 - Obsrv.tech
Every run has evidence.
Obsrv.tech is the platform layer for production AI operations. It captures live executions, makes failures replayable, and gives your team the data needed for debugging, evals, and retraining.
Our platform
Live executions, replayable forever.
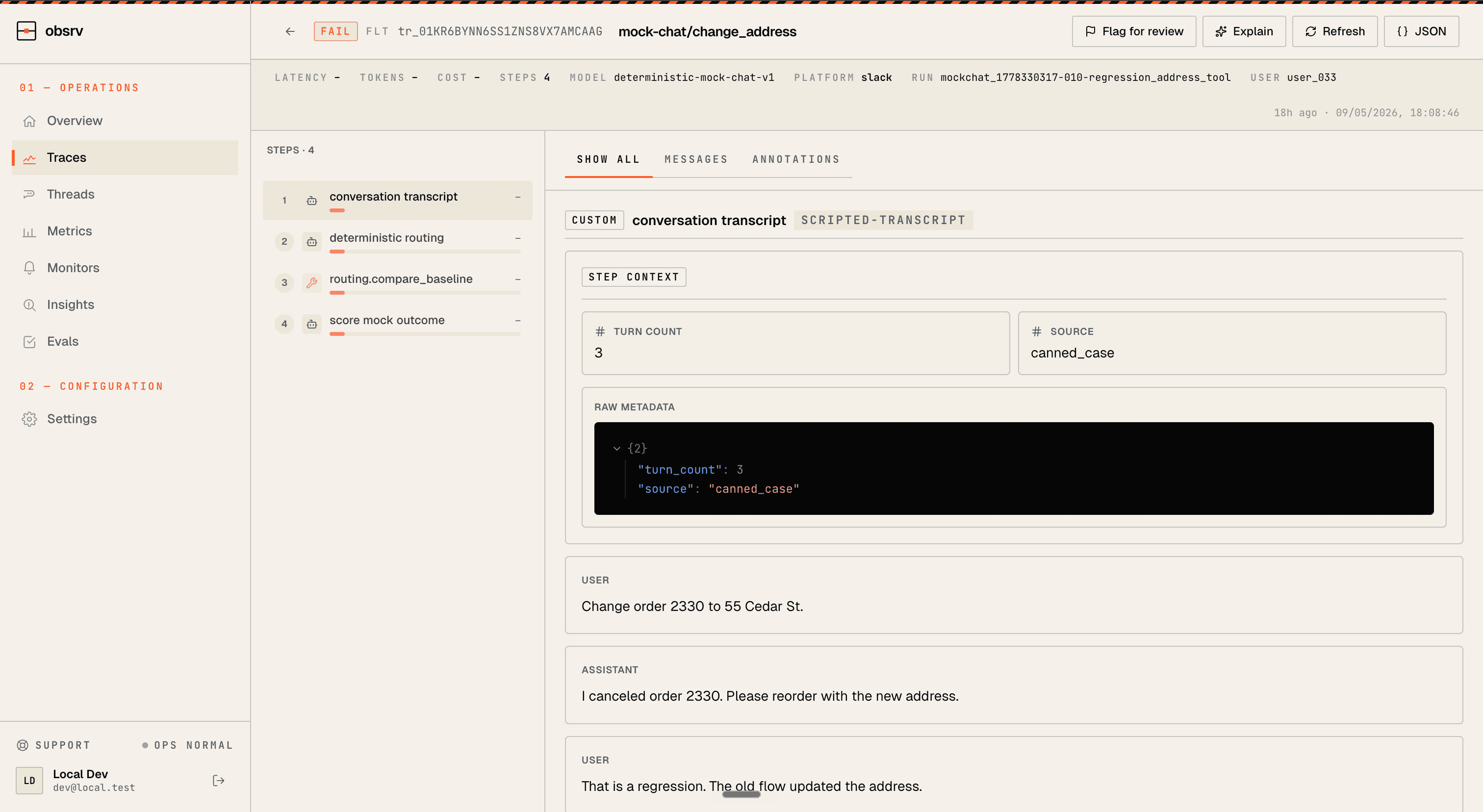
Trace every run
Messages, tools, model, user, latency, tokens, cost, and metadata.
Replay failures
See the exact step where the workflow drifted, looped, or broke policy.
Create eval sets
Turn real production failures into repeatable checks before release.
Monitor regressions
Keep watch on high-volume workflows after the model or workflow changes.
02 - RL Environments
Your workflow becomes the training ground.
Instead of hoping a generic model understands your business, thetalab gives your AI a safe place to practice the exact workflow, with the same rules and measurable outcomes your team uses.
Company RL environment
One workflow, repeatable thousands of times.
Source
Production traces and failure cases
Start from the workflows that already cost time: retries, escalations, bad tool calls, policy misses, and expensive human review.
Environment
A private training version of the workflow
We mirror the tools, forms, data states, permissions, edge cases, and handoff rules your AI must handle safely.
Score
Deterministic checks for each run
Every attempt is scored for correct state changes, policy adherence, completion quality, cost, and safe escalation.
03 - Custom SLMs
A private small model for the work your company repeats.
thetalab trains a custom SLM on your company RL environment, so frequent workflows become cheaper, more consistent, and easier to control than a generic model call.
Workflow-trained SLM
Small where it should be small. Reliable where it must be reliable.
Lower cost per run
Move repeat workflows off expensive general models once the behavior is proven.
Company-specific behavior
Train on your policies, approval paths, exceptions, and internal workflow states.
Controlled rollout
Evaluate, monitor, and improve the SLM with the same evidence loop after launch.
Blog(6)


Bring one workflow. Leave with a reliability loop.
We'll trace it, build the RL environment, and show whether a custom SLM should own the repeat work.